

EdgeOne 的免费模型 API 接口
最近看 EdgeOne 文档时,我注意到这篇: 边缘 AI
文档里提到,可以通过 EdgeOne 边缘函数快速调用 DeepSeek 模型能力接入自己的站点。这个思路很实用:模型调用发生在边缘侧,前端不直接暴露真实密钥,部署和安全性都更友好。
另外,官方还提供了一个快速部署对话站点的演示方案。当前边缘 AI 处于限时免费 Beta,文档中给出的模型与每日调用额度大致如下:
| 模型 ID | 每日调用次数限制 |
|---|---|
| @tx/deepseek-ai/deepseek-v3-0324 | 50 |
| @tx/deepseek-ai/deepseek-r1-0528 | 20 |
| @tx/deepseek-ai/deepseek-v32 | 50 |
对应的最佳实践文档: 使用 DeepSeek-R1 模型快速搭建对话 AI 站点
演示站地址: https://deepseek-r1-edge.edgeone.app
我在这个站点里看到两个可选模型:DeepSeek-R1(0528) 和 DeepSeek-V3(0324)。体验下来速度和稳定性都不错,于是顺手做了一次网络请求观察,看看前端到底是怎么调用模型的。
抓包观察
在发送消息时,页面会发起一个 POST 请求:
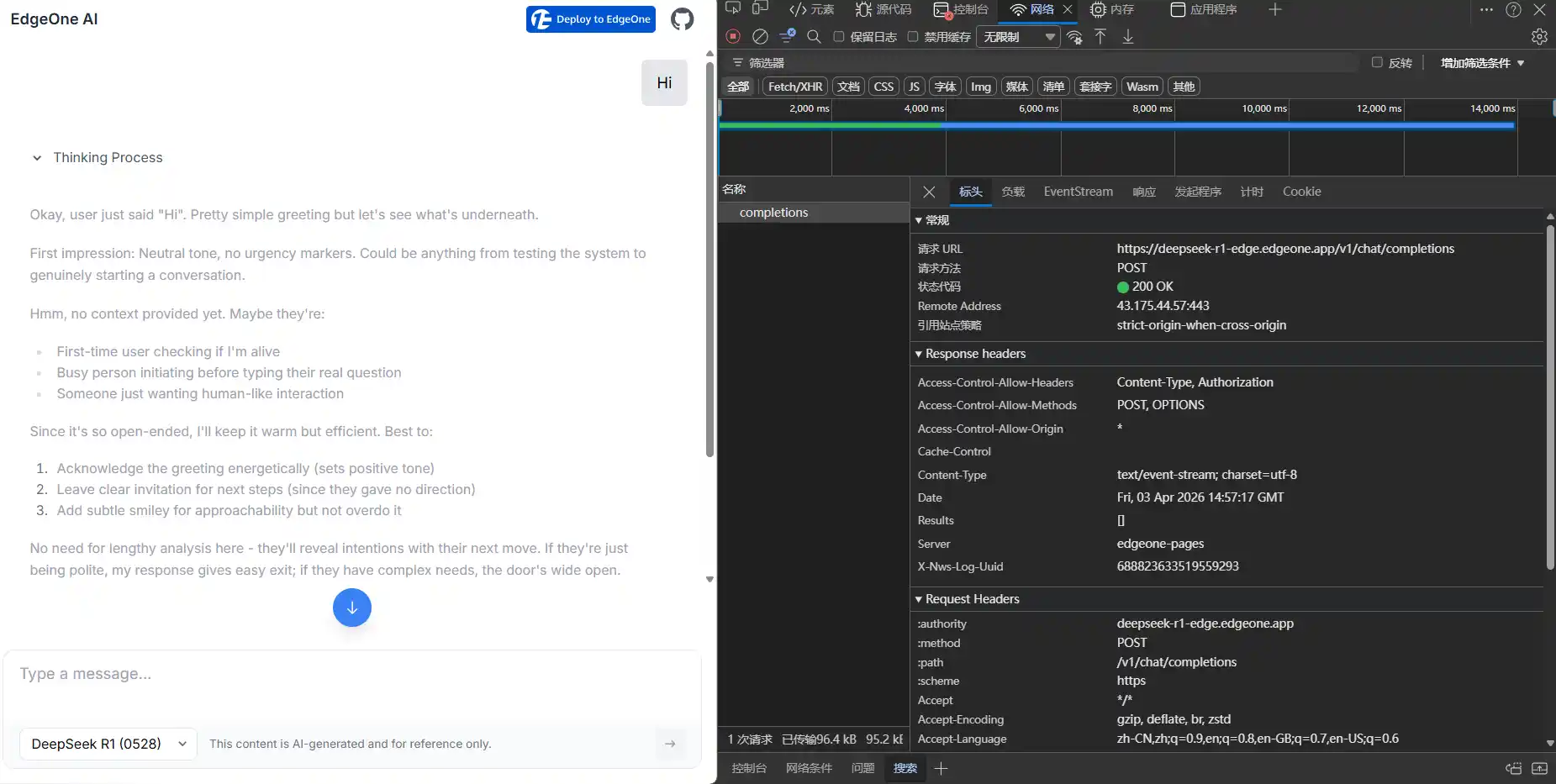
请求地址是:https://deepseek-r1-edge.edgeone.app/v1/chat/completions
这个路径格式和 OpenAI 兼容接口非常接近。请求负载示例如下:
{"messages":[{"role":"user","content":"Hi"}],"network":false,"model":"@tx/deepseek-ai/deepseek-r1-0528"}可以看到模型字段使用的是:@tx/deepseek-ai/deepseek-r1-0528。
切换模型后,会变成:@tx/deepseek-ai/deepseek-v3-0324。
这与文档里给出的模型 ID 是一致的。
再看响应内容,会持续返回 chat.completion.chunk,典型的 SSE 流式输出形态。例如:
data: {"id":"...","object":"chat.completion.chunk","choices":[{"delta":{"reasoning_content":"Okay"}}],...}data: {"id":"...","object":"chat.completion.chunk","choices":[{"delta":{"reasoning_content":","}}],...}data: {"id":"...","object":"chat.completion.chunk","choices":[{"delta":{"reasoning_content":" user"}}],...}也就是说,前端对话体验本质上就是通过兼容 OpenAI 格式的流式接口在返回内容。
那么,我能不能也尝试在本地调用这个接口呢?
Cherry Studio 实测
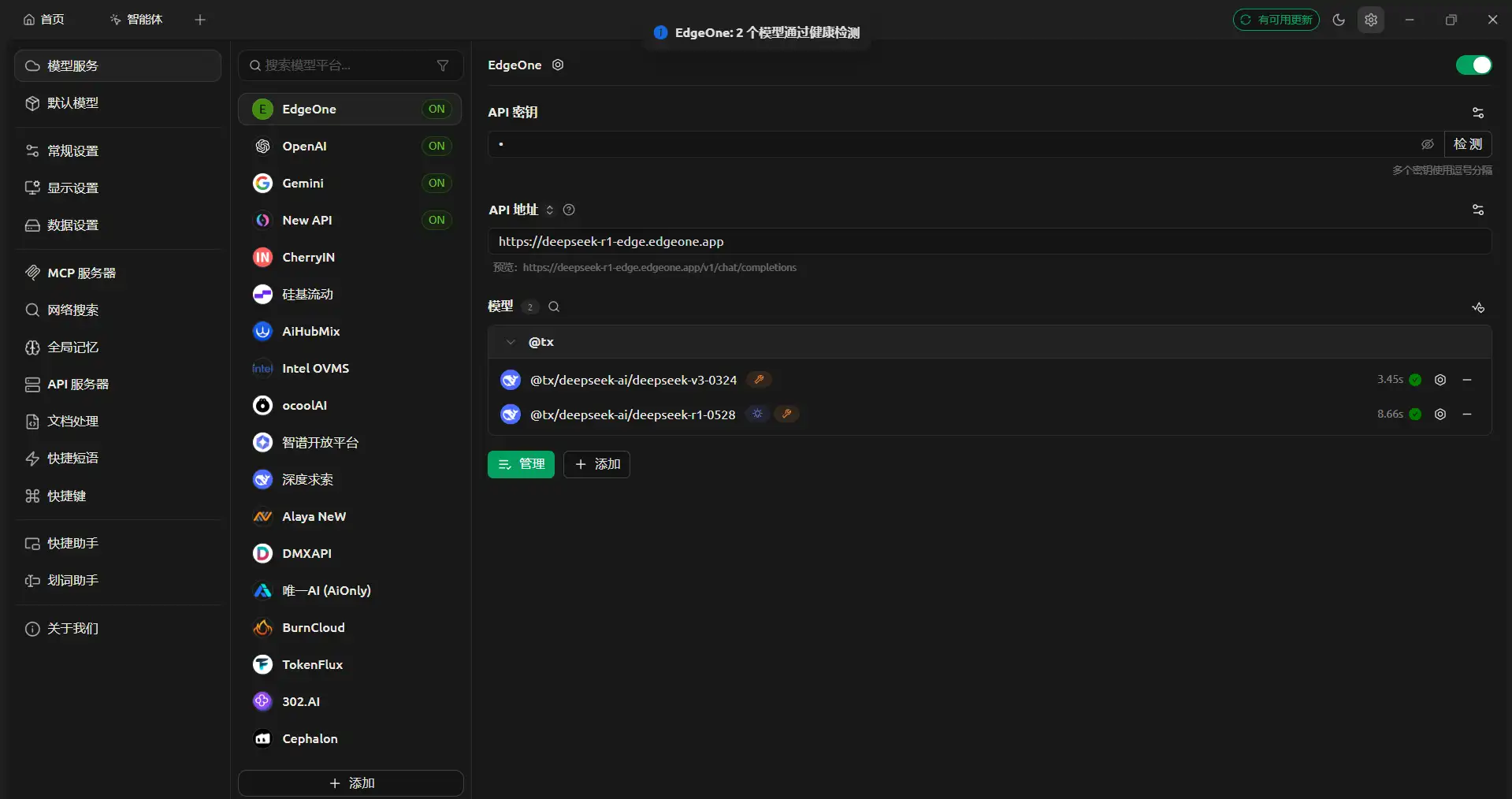
接着我在 Cherry Studio 里添加了一个自定义 OpenAI 格式供应商,配置如下:
- 接口地址:
https://deepseek-r1-edge.edgeone.app - API Key:任意字符串(用于通过客户端表单校验)
- 模型 ID:
@tx/deepseek-ai/deepseek-r1-0528@tx/deepseek-ai/deepseek-v3-0324
连接测试截图:
对话测试截图:
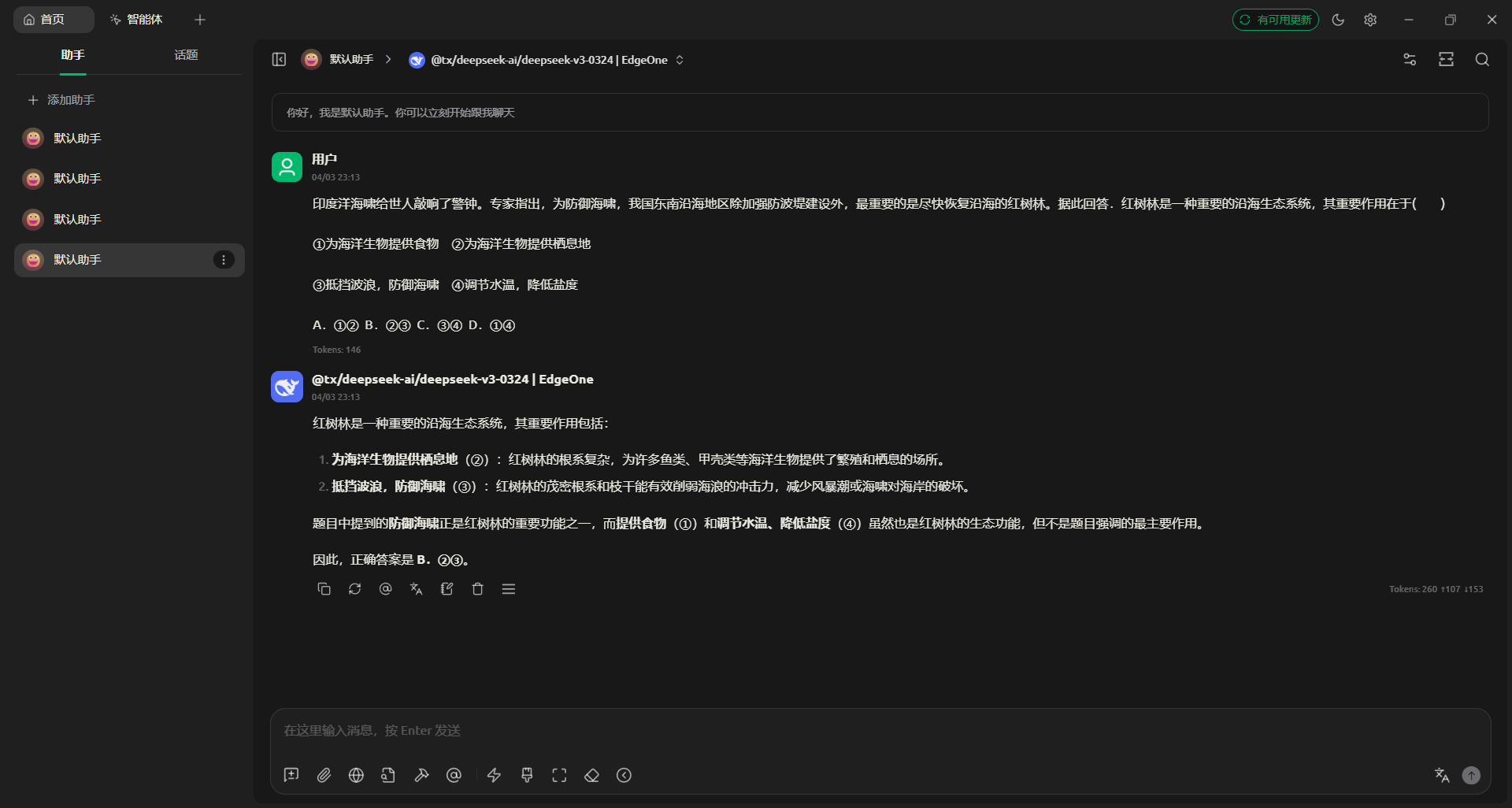
实测可正常返回,并支持流式输出,交互体验和常见 OpenAI 兼容接口基本一致。
小结
从这次测试看,如果站点使用了 EdgeOne 的边缘 AI 服务确实暴露了可直接请求的对话接口,而且格式与 OpenAI 兼容高度一致。
如果未来边缘AI在这些环节配置不足,就可能出现被非预期调用、额度被消耗或成本失控的问题。所以这可以说是一个设计缺陷吗?